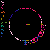|
Consensual Domain
Considering C5's history of explorations into non-model based and distributed, data mapping and visualization, in addition to my emphasis on investigation into autopoietic data systems, Mapping the Web Infome is a very good opportunity to further these investigations. This new tool designed to crawl through the vast Web body based on varied strategies and implementations, made available to the artists for exploration, enables myriad possibilities for data search and visualization. In Lisa Jevbratt's original invitation to participate in the project she wrote: "The Web is a space created and constituted by language. It's made up of protocols and code. It's not old. We know it's languages, we designed them. Yet the whole made up of the parts could now have reached a level of complexity and richness that makes it interesting to relate it to that mysterious room of the human genome. To turn around and look at it from the outside, as a system to unveil, with a language for us to decipher." It is with this language that I'm primarily concerned, specifically in the area of consensual domains. Autopoiesis as related to data, could potentially be realized in linguistic, consensual domains. Language, as a consensual domain, is a patterning of behavior that possesses a shared orientation. So in undertaking my crawler strategy, I was interested in having the data reveal where these consensual domains of Web language may emerge. The programming team developed a system for determining the most used words (the number is variable dependent on user input) on any given file, which I incorporated into my crawler parameters. I began with 10 varied subject searches with the intention of probing the language of diverse fields: architecture, economics, television, sports, zoology, fashion, cosmology, cooking, medicine, and raves. It's just a beginning; much more data will need to be collected to cover the expanse of data for a larger sampling. Perhaps a new function can be worked into the crawler system that would launch associative searches that are automatically implemented as the search proceeds - as in the associative connections that occur whenever our minds run with anything. The first consensual domain revealed is in the language of the underbelly of the Web that is formed in the vocabulary of its coding: HTML, JavaScript, Perl, etc. This mapping created before scripting vocabulary was filtered, reveals this consensual domain of scripting language. This is interesting in itself, being the root language of the system, but in order to go on to the surface level of the social languaging of the Web body, the scripting language was filtered. At your right are the 10 data visualizations determined by their usage of the 50 most used words, calculated in the 3000 files that were searched.
The listing of words runs down the left side of the map in a gradated color system, with white being the most used word on down through a dark purple for the least used of the 50 in the list. A layered circle mapping of the links contains lines who's colors map to the word list: a pink line being a page that contained one of the more frequently appearing words, while a purple line contains one of the lesser used words in the list. A cursory comparison of the mappings reveals a few interesting trends. The top spot for "research" would seem to reveal the academic and military roots, which still make up a large portion of the Web and are apparent in the system. Areas like architecture and sports are very well represented, being high in the list. They're also very self-referential and well indexed as revealed in their high concentrations of pink. Based on its representation in these mappings, sports appear to be big business (business being another unsurprisingly high roller). Even on a test run, where I implemented a "sex" search into the mapping, "sports" stayed very high in the list with "sex" appearing just above the median. An interesting comment on our culture perhaps; particularly American culture, with "american" appearing rather high in the list. Areas like fashion and raves, were the most decentralized in their search results making for the most aesthetically interesting mappings, which seems strangely appropriate. The potential richness of data associations that emerge in this small sampling seem to point to what could be a wealth of non-linear mappings that just may reveal some useful insight into the explorations of consensual domains of the Web. It remains to be seen what the data wants to say.
|
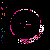
economics
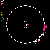
television
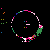
sports
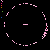
zoology
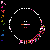
fashion
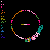
cosmology
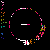
cooking
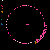
medicine
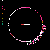
raves